Das Geheimnis der Sicherung von Unternehmensdaten beim Einsatz generativer KI? Fragen Sie einfach Guardian.
Januar 24, 2025
Nutzen Sie die Leistung der generativen KI, um die Effizienz zu steigern und die Kosten zu senken, ohne die Datensicherheit zu gefährden.
Generative KI ist auf dem Vormarsch, integriert sich in die Geschäftsprozesse von Unternehmen und verspricht optimierte Abläufe und Kosteneinsparungen. Allerdings haben Bedenken über die Preisgabe sensibler Daten an Large Language Models (LLMs) Unternehmen zögern lassen, die Technologie zu übernehmen - vor allem, wenn es um kritische Informationen über ihre Prozesse, Technologien und Nutzer geht.
Eine aktuelle Cisco-Umfrage ergab, dass mehr als jedes vierte Unternehmen generative KI aufgrund von Bedenken hinsichtlich des Datenschutzes und der Datensicherheit verboten hat. Dies verdeutlicht das erhebliche Spannungsverhältnis zwischen dem Wunsch nach Innovation durch KI und der kritischen Notwendigkeit, Unternehmensdaten zu schützen.
Untersuchung der Risiken der Datenexposition
Unternehmen stehen bei der Sicherung von zwei Arten von Daten vor besonderen Herausforderungen:
- Strukturierte Daten: In relationalen Datenbanken als Tabellen und Spalten gespeichert
- Unstrukturierte Daten: Zu finden in Dokumenten, Richtlinien, Prozessen, Bildern und Wissensartikeln
LLMs benötigen Zugang zu Daten, um zu lernen und kontextabhängige Ergebnisse zu erzeugen. Die Freigabe von Unternehmensdaten für LLMs birgt jedoch zusätzliche Risiken, wie in diesen Szenarien dargestellt:
Szenario 1: Gefährdung sensibler Geschäftsdaten
Stellen Sie sich vor, ein ERP-Anbieter verwendet LLMs zur Unterstützung der NLP-basierten Rechnungserstellung. Durch die Bereitstellung sensibler Daten wie Teilenummern, Stückpreisen und Rabattrichtlinien riskiert das Unternehmen eine indirekte Gefährdung. Wenn ein anderer Benutzer fragt: "Was ist der typische Rabatt für gemeinnützige Organisationen?", könnte er versehentlich sensible Erkenntnisse preisgeben, die das LLM gelernt hat.
Diese Problem der Datenexposition tritt auf, wenn LLM unbeabsichtigt gelernte Informationen außerhalb des vorgesehenen Kontexts verwenden, was zu potenziellen Geschäftsrisiken führt.
Szenario 2: Compliance-Verstöße in verschiedenen Regionen
Unternehmen, die in mehreren Regionen tätig sind, müssen sich an strenge Datenschutz- und Lokalisierungsvorschriften halten. So dürfen beispielsweise personenbezogene Daten europäischer Mitarbeiter nicht außerhalb Europas weitergegeben werden. Die Weitergabe solcher Daten an LLMs könnte gegen folgende Bestimmungen verstoßen Datenverarbeitungsverträge und verletzen die Grenzen der Gesetzgebung und der Einhaltung von Vorschriften.
Aufkommende Bedrohungen und Schwachstellen
Mit der Weiterentwicklung der generativen KI steigen auch ihre Risiken. Frühe Anwender müssen Schwachstellen in der Infrastruktur, in Netzwerken und Anwendungen berücksichtigen. Einige bemerkenswerte Risiken umfassen:
- LLM-Datenlecks: Unbeabsichtigte Offenlegung von sensiblen geschützten Informationen
- Prompt-Injektionsangriffe: Manipulative Abfragen, um vertrauliche Daten zu extrahieren
- Modell Diebstahl: Der unbefugte Zugriff oder die Manipulation von LLM-Modellen
Aktuelle Tools und ihre Grenzen
Zwar bieten LLM-Anbieter und Drittunternehmen Tools für die Datensicherheit an, doch konzentrieren sich diese Lösungen in erster Linie auf unstrukturierte Daten (wie Dokumente). Das eigentliche Problem der Offenlegung strukturierter Daten wird dabei oft nicht angegangen.
So können beispielsweise Datenmaskierungstechniken sensible Informationen während der LLM-Schulung verbergen. Sie verhindern jedoch nicht, dass LLMs unbeabsichtigt Trends oder Durchschnittswerte erfahren, die über Organisationsgrenzen hinweg missbraucht werden könnten.
Eine ganzheitliche Lösung: Der Ansatz von Alert Enterprise
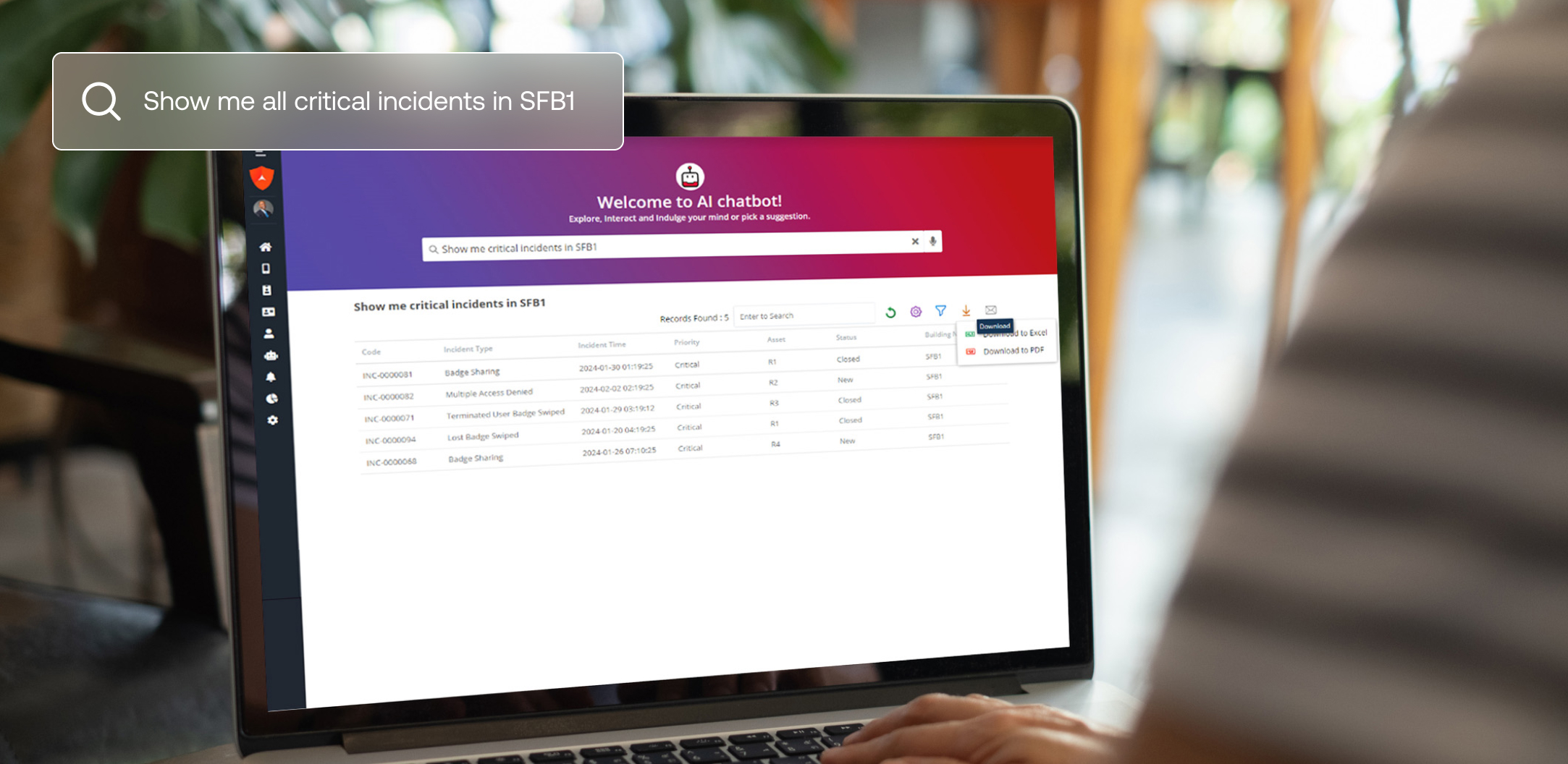
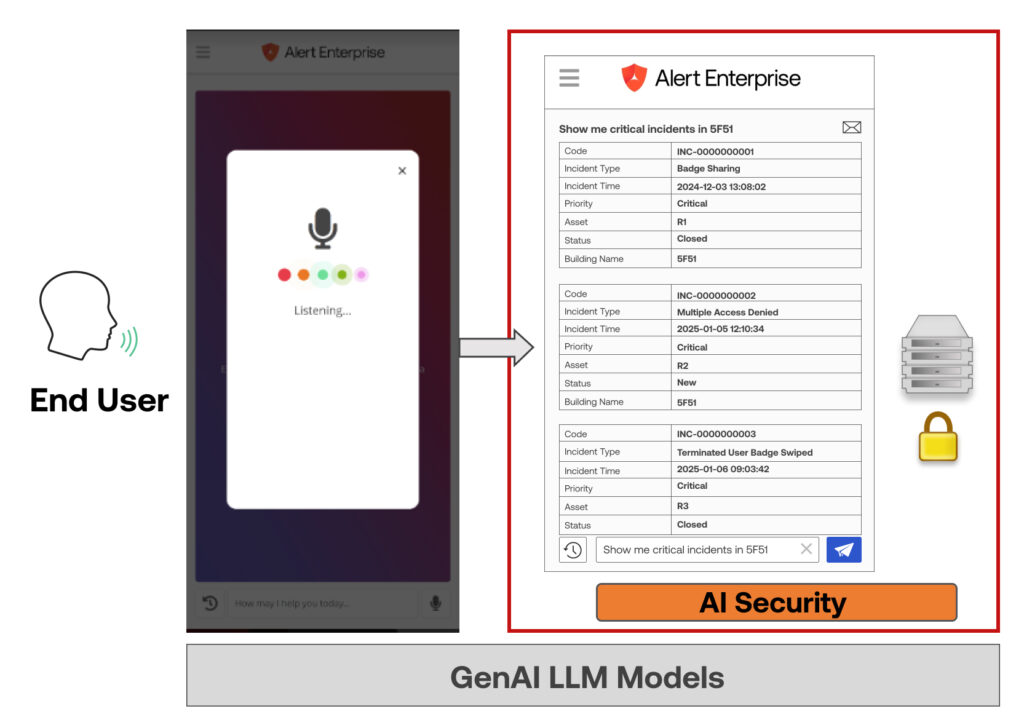
Der effektivste Weg, Unternehmensdaten zu schützen, besteht darin, den Zugriff von LLMs auf tatsächlich strukturierte Daten vollständig zu verhindern. Alert Enterprise hat eine patentierte Technologie entwickelt, um dies zu erreichen, indem LLMs nur für folgende Zwecke eingesetzt werden Metadaten, wie Tabellenstrukturen und Entitäten. Der LLM verwendet Natural Language Processing (NLP), um Abfragen in Metadaten umzuwandeln, die die Anwendung dann in maschinenlesbare Syntax übersetzt, um Daten sicher abzurufen.
Unser Guardian Security AI Chatbot basiert auf dieser Technologie und ermöglicht es Nutzern, Fragen zur Datenanalyse in natürlicher Sprache zu stellen. Der Chatbot liefert sofortige, präzise Antworten, ohne sensible Daten zu gefährden.
Dieser innovative Ansatz gewährleistet:
- LLMs haben nie Zugang zu Rohdaten, was Risiken ausschließt.
- Unternehmen behalten die volle Kontrolle über ihre strukturierten Daten und gewährleisten die Einhaltung von Vorschriften in allen Regionen und Abteilungen.
Möchten Sie mehr erfahren?
Entdecken Sie unser bahnbrechendes generatives KI-Datenschutzpatent hier.





